はじめに
本記事は、 DeNA Advent Calendar 2020 の 11 日目の記事です。
突然ですが、「コンパイラのコードを読んでみよう」なんて言われても、「どうせ巨大で難解で複雑なロジックを理解しないと読めないんでしょ?」と思いませんか。
コンパイラの構造を理解しようとしても聞いたことのないような専門用語がずらりと並び、コードを読もうとしたらそれらをすべて完全に理解してないと一行も理解できないんじゃないか...。Go のコンパイラ gc のソースコードを読むまでは、私もそう思っていました。
しかし、あまりにも暇な休日のある日、思い立って gc のコードを読んでみました。すると、「コンパイル」という難解な響きの処理も、一つひとつを小さなタスクに分解することで、少しずつ読み進めることができると分かったのです!
何よりも感動したことは、 gc そのものが全て Go で書かれていて、コードはシンプルで読みやすく、コメントもかなり丁寧であることです。しかも、gc のコード上では Go の様々な機能が思う存分活用されていて、大変興味深い部分に溢れています。
この記事では、コンパイラについて学んだことがない Gopher 向けに、Go の公式コンパイラの一つである gc のコードを読む楽しさを伝えることを目指します。
対象とする読者
想定している読者は以下の通りです。コンパイラについてよく知らなくても、Go の基礎的な文法を理解している方であれば読み進められるように書いています。
対象とするバージョンは go1.15.6 です。
お断り
コンパイラに関する詳細な知識を求めている方へ:
本記事のコードリーディングでは、 AST への変換までを対象としています。 また、本記事では再帰降下構文解析の具体的な実現手段や、SSA・機械語への変換の手順などは紹介していません。 あくまで gc の概観を理解し、より詳細な理解に進むためのステップとしてお読み頂ければ幸いです。
コンパイラとは
まず、コンパイラとは何かをおさらいしましょう。 コンパイラとは、高水準なプログラミング言語で書かれたプログラムを、機械語やアセンブリ言語やバイトコードなどへ変換するプログラムを指します。
次に、一般的なコンパイラによる処理の流れを見ていきましょう。
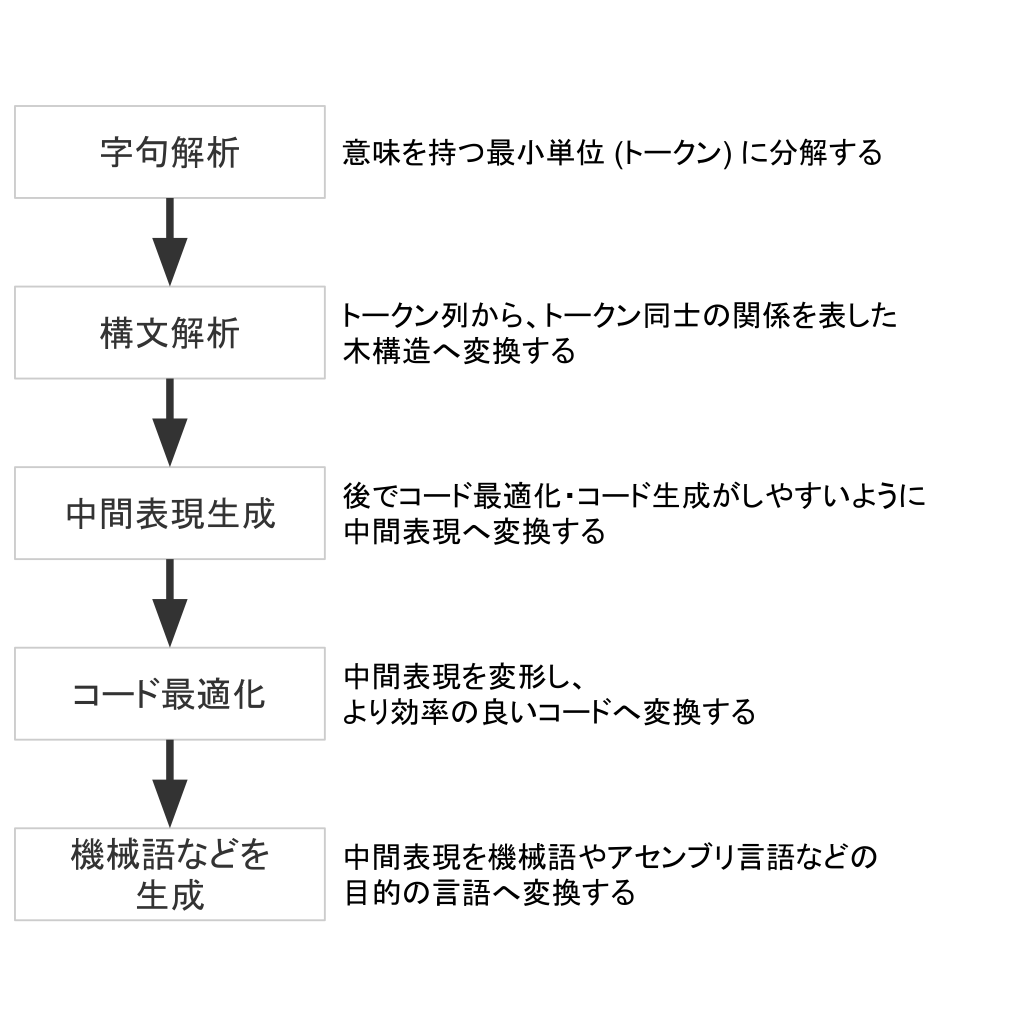
字句解析 (scan)
字句解析 (scan) は、プログラムをトークンの列へ変換します。トークンとは、「意味を持つ最小単位」を指します。例えば、 x := 1 + 23 という文について見てみましょう。意味を持ったまま := をこれ以上分解することはできませんので、 := はトークンであるといえます。これは x や 1 などにも同じことが言えます。よって、 x := 1 + 23 は x := 1 + 23 というトークンの列へ変換されます。
構文解析 (parse)
構文解析 (parse) は、トークン列からトークン同士の関係を表す木構造へ変換します。
例えば、 x := 2 + 3 * 6 は以下のような木構造で表現することができます。
このように、構文解析によって得られた木構造を 構文木 と呼びます。
:=
/ \
x +
/ \
2 *
/ \
3 6
また、これらの構文木からコード生成に不要な部分を削除したものを、 AST (abstract syntax tree; 抽象構文木) と呼びます。 多くの場合、構文解析ではトークン列から構文木に変換した上で、さらに AST へ変換します。
中間表現生成
プログラムをより効率的に動作させるために、多くのコンパイラはコードの最適化を行います。 そのために、コンパイラが最適化しやすいような形式 中間表現 に変換します。 例えば、 gc では AST を SSA 形式と呼ばれる中間表現の一種へ変換します。
SSA 形式 は 静的単一代入形式 とも呼ばれ、それぞれの変数が一度だけ代入されるように定義される形式です。
例えば、以下のような変換が行われます。 以下の例では、 SSA 形式に変換することによって a1 への代入が不要な処理であることがより明確になりました。このように、最適化を行う上で SSA 形式への変換は非常に便利です。
// before a := 1 a = 2 b = a + 1 // after a1 := 1 a2 := 2 b1 := a2 + 1
gc とは
gc は cmd/compile とも呼ばれ、普段多くの人々が利用している、公式の Go コンパイラの1つです。
gc のコードはgithub.com/golang/go/tree/master/src/cmd/compileに置かれています。README.md も丁寧に書かれていて、コードにもきちんとコメントが書かれているため、コンパイラに対する知識が少ない状態でも読み進めることができます。
gc のパッケージ構成
gc は cmd/compile パッケージに実装されています。
それでは cmd/compile パッケージの構成を見てみましょう。
gc の実装のほぼ全ては cmd/compile/internal パッケージに置かれており、exported な関数や構造体や変数はありません。
コアとなる処理は cmd/compile/internal/gc パッケージに格納されており、 gc.Main を中心としてコンパイルが行われ、必要に応じて他のパッケージが呼び出されます。
cmd/compile ├── internal │ ├── gc │ │ gc のコアとなるパッケージ │ │ 構文木 -> AST -> SSA(中間表現) へ変換する │ │ │ ├── syntax │ │ 字句解析・構文解析を行うパッケージ │ │ │ ├── ssa │ │ SSA の最適化を行うパッケージ │ │ │ ├── logopt │ │ json オプションを指定時の処理を行うパッケージ │ │ │ ├── test │ │ テスト │ │ │ ├── types │ │ Go の型を表現するパッケージ │ │ │ │ 以下はすべて SSA からそれぞれの │ │ アーキテクチャに向けた機械語を生成するパッケージ │ ├── amd64 │ ├── arm │ ├── arm64 │ ├── mips │ ├── mips64 │ ├── ppc64 │ ├── riscv64 │ ├── s390x │ ├── wasm │ └── x86 └── main.go
gc によるコンパイルのフロー
それでは、gc によるコンパイルのフローを追っていきましょう。

初めに、コンパイル対象となるそれぞれのソースファイルは、字句解析・構文解析を経て構文木となり、さらに AST へ変換されます。 次に、型チェックが完了した AST は SSA 形式の中間表現へ変換されます。その後、中間表現は最適化されたのち、機械語へと変換されます。
コードリーディング
最後に、実際のコードを読んでみましょう。本記事では字句解析・構文解析・AST への変換までを対象とします。
コンパイルの開始とファイルの読み込み
gc.Main : 初期化処理
gcのメイン処理は main.Main() にはほとんど書かれておらず、実際には 700 行近い関数である gc.Main() が中心となって行われます。gc.Main の冒頭の約 200 行はコマンドライン引数やオプションに関する処理で、実際にコンパイルの対象となるファイルを字句解析・構文解析する処理は 570 行目前後から行われます。
それでは、実際にそれぞれのファイルに対する処理が開始される gc.Main の 561 行目から見てみましょう。
まず、 initUniverse() が universe ブロックを用意します。
universe ブロックはすべてのソースファイルが展開されるブロックで、これから読み込まれるあらゆるコードがこのブロックの下に展開されていきます。
initUniverse() は、 int, bool, error などの基本型や true, false, iota などの定数、ゼロ値 nil などを初期化し、これを universe ブロックに宣言します。
func Main(archInit func(*Arch)) {
// 中略
{ /* highlight-range{1} */ }
initUniverse()
dclcontext = PEXTERN
nerrors = 0
autogeneratedPos = makePos(src.NewFileBase("<autogenerated>", "<autogenerated>"), 1, 0)
timings.Start("fe", "loadsys")
loadsys()
timings.Start("fe", "parse")
lines := parseFiles(flag.Args())
timings.Stop()
timings.AddEvent(int64(lines), "lines")
finishUniverse()
ここが面白い
cmd/compile/gc/universe.go を読むと、実は universe ブロックに builtinpkg という偽のパッケージが宣言されていて、そこに基本型や定数が宣言されていくことが分かります。
// builtinpkg is a fake package that declares the universe block. var builtinpkg *types.Pkg
// initUniverse initializes the universe block. func initUniverse() { lexinit() typeinit() lexinit1() }
例えば、 iota も以下のように初期化されて builtinpkg の中に置かれています。
私たちが普段何気なく使っている nil や iota も、実は架空のパッケージに定義されていると思うと、ちょっと不思議ですね。
// lexinit initializes known symbols and the basic types. func lexinit() { // 中略 s = builtinpkg.Lookup("iota") s.Def = asTypesNode(nod(OIOTA, nil, nil)) asNode(s.Def).Sym = s asNode(s.Def).Name = new(Name) }
ちなみに、gc では builtinpkg のようなグローバル変数が数多く宣言されています。普段避けがちなグローバル変数も、使い時を間違えなければ便利ですが、これらの大量に宣言されたグローバル変数をうまく整理すれば、 gc へのコントリビューションを達成できるかもしれませんね。
次に、 loadsys() が低レベルなランタイム関数をロードします。
例えば、おなじみの定義済み関数 panic() の実装である gopanic() もここでロードされます。ランタイム関数の実装は runtime に置かれています。
そして、いよいよ parseFiles() 関数によってそれぞれのファイルが並列に字句解析・構文解析され、ファイルごとに構文木へ変換されます。
次は、 parseFiles() を見ていきましょう。
func Main(archInit func(*Arch)) {
// 中略
initUniverse()
dclcontext = PEXTERN
nerrors = 0
autogeneratedPos = makePos(src.NewFileBase("<autogenerated>", "<autogenerated>"), 1, 0)
timings.Start("fe", "loadsys")
{ /* highlight-range{1} */ }
loadsys()
timings.Start("fe", "parse")
{ /* highlight-range{1} */ }
lines := parseFiles(flag.Args())
timings.Stop()
timings.AddEvent(int64(lines), "lines")
finishUniverse()
gc.parseFiles
それでは、 gc.parseFiles() の中身を見ていきましょう。
1つのソースファイルから得られる情報は noder 構造体で表現されます。
まず、 goroutine の中で syntax.Parse() によって字句解析・構文解析が行われ、得られた構文木が noder.file へ格納されます。
次に、noder.node() を呼び出し、この noder.file から AST を生成します。
// parseFiles concurrently parses files into *syntax.File structures.
// Each declaration in every *syntax.File is converted to a syntax tree
// and its root represented by *Node is appended to xtop.
// Returns the total count of parsed lines.
func parseFiles(filenames []string) uint {
noders := make([]*noder, 0, len(filenames))
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
// 補足: [STEP1] ソースファイルから構文木へ
for _, filename := range filenames {
p := &noder{
basemap: make(map[*syntax.PosBase]*src.PosBase),
err: make(chan syntax.Error),
}
noders = append(noders, p)
go func(filename string) {
// 補足: セマフォで同時に開くファイル数を `runtime.GOMAXPROCS(0)+10` 個まで制限している
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
base := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Msg: err.Error()})
return
}
defer f.Close()
// 補足: 構文木を生成し p.file に格納する
// syntax.Parse で発生した error は
// p.error 関数で記録される
p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches) // errors are tracked via p.error
}(filename)
}
// 補足 [STEP2] 構文木から AST へ
var lines uint
for _, p := range noders {
for e := range p.err {
p.yyerrorpos(e.Pos, "%s", e.Msg)
}
p.node() // 補足: AST への変換はここで行われる
lines += p.file.Lines
p.file = nil // release memory
if nsyntaxerrors != 0 {
errorexit()
}
// Always run testdclstack here, even when debug_dclstack is not set, as a sanity measure.
testdclstack()
}
localpkg.Height = myheight
return lines
}
ここが面白い
gc.parseFiles では、 channel を利用したセマフォで同時に開くファイル数を runtime.GOMAXPROCS(0)+10 個まで制限しています。
これは、 too many open files を防ぐために使われています (golag/go/#21621)。
訂正: 「channel を利用してエラーの伝搬を行っている」と書いていましたが、誤りでした。
また、 goroutine でそれぞれのファイルごとに字句解析・構文解析までを行っていることから、 CPU を余らせることなく処理を行っています。 Go の高速なコンパイルは、このような地道な工夫によって支えられているのだなあ、と感じました。
noders := make([]*noder, 0, len(filenames)) // Limit the number of simultaneously open files. sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10) for _, filename := range filenames { p := &noder{ basemap: make(map[*syntax.PosBase]*src.PosBase), err: make(chan syntax.Error), } noders = append(noders, p) go func(filename string) { // 補足: セマフォで同時に開くファイル数を `runtime.GOMAXPROCS(0)+10` 個まで制限している sem <- struct{}{} defer func() { <-sem }() defer close(p.err) base := syntax.NewFileBase(filename) f, err := os.Open(filename) if err != nil { p.error(syntax.Error{Msg: err.Error()}) return } defer f.Close() p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches) // errors are tracked via p.error }(filename) }
構文解析
syntax.Parse
gc.parseFiles() から呼び出される syntax.Parse() は、コメントにある通り 1 つのソースファイルから構文木を生成します。 gc は再帰降下構文解析 (recursive descent parsing) という方式で構文解析を行います。構文解析器は parser 構造体で表現され、字句解析器である scanner 構造体が埋め込まれています。字句解析を進めながら構文解析を行います。
cmd/compile/syntax/parser.go [開く]
type parser struct {
file *PosBase
errh ErrorHandler
mode Mode
pragh PragmaHandler
{ /* highlight-range{1} */ }
scanner // 補足: ここに scanner が埋め込まれている
base *PosBase // current position base
// 中略
}
scanner は現在見ているコード上の位置や、現在見ているトークンの情報などを持ちます。
cmd/compile/syntax/scanner.go [開く]
type scanner struct {
// 中略
// current token, valid after calling next()
line, col uint // 補足: 現在見ているコード上の位置
blank bool // line is blank up to col
tok token // 補足: 現在見ているトークンの情報
cmd/compile/syntax/syntax.go [開く]
// Parse parses a single Go source file from src and returns the corresponding
// syntax tree. If there are errors, Parse will return the first error found,
// and a possibly partially constructed syntax tree, or nil.
//
// If errh != nil, it is called with each error encountered, and Parse will
// process as much source as possible. In this case, the returned syntax tree
// is only nil if no correct package clause was found.
// If errh is nil, Parse will terminate immediately upon encountering the first
// error, and the returned syntax tree is nil.
//
// If pragh != nil, it is called with each pragma encountered.
//
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
// 補足: 構文解析器(parser) と 字句解析器(scanner) を初期化する
p.init(base, src, errh, pragh, mode)
// 補足: next() は埋め込まれている scanner がレシーバの関数
// ここでの呼び出しは scanner の現在位置を初期化するために必要
p.next()
// 補足: ここで字句解析と構文解析の処理が呼び出され、結果が戻される
return p.fileOrNil(), p.first
}
syntax.fileOrNil
syntax.fileOrNil() は、前述した再帰降下構文解析を行う関数です。 fileOrNil() は、まず pacakge 句と import 文を構文解析した後、トップレベルスコープに定義された定数、変数、型、関数について構文解析していきます。
ちなみに、以下にあるように syntax パッケージではしばしば関数の頭や関数中のコメントに // TypeSpec = identifier [ "=" ] Type . のような文字列が書かれていると思いますが、これは BNF (バッカスナウア記法) と呼ばれる記法を拡張した EBNF と呼ばれる記法で、プログラミング言語の文法を定義するためにしばしば用いられます。関数の頭に EBNF のコメントが書かれている場合は、左辺について構文解析している関数だと考えて頂ければ読み進められると思います。
加えて、{ } が省略可能で繰り返し可能であること、 [ ] が省略可能であることをそれぞれ表していることも覚えておくと読みやすいです。
cmd/compile/syntax/parser.go [開く]
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File {
まずは初期化処理から見ていきましょう。このファイルについての構文解析の結果は File 構造体に詰められます。
cmd/compile/syntax/parser.go [開く]
func (p *parser) fileOrNil() *File {
if trace {
defer p.trace("file")()
}
// 補足: 構文解析の結果は File 構造体に詰められる
f := new(File)
f.pos = p.pos()
File 構造体の定義を見てみましょう。PkgName フィールドはパッケージ名を持ちます。 DeclList フィールドはトップレベルスコープに宣言された定数、変数、型、関数と import をすべて持つスライスです。
トップレベルスコープとは、各ファイルの中で最も外側にあるスコープを指します。定数、変数、型、関数 というそれぞれ全く異なる性質を持つ要素の宣言が、同じ DeclList というスライスの中に格納されているのは、ちょっと意外ですね。
// package PkgName; DeclList[0], DeclList[1], ... type File struct { Pragma Pragma PkgName *Name DeclList []Decl Lines uint node }
ここが面白い
上で少し触れましたが、import、定数、変数、型、関数の宣言は同じ Decl というインターフェイスを持つ構造体として扱われています。 Decl は Declaration(宣言) の略語です。
type Decl interface { Node aDecl() }
定数の宣言、型の宣言はそれぞれ、ConstDecl, TypeDecl という構造体で表現されています。
ところで、いずれの構造体にも decl という構造体が埋め込まれていますね。一体これは何でしょう?
// NameList // NameList = Values // NameList Type = Values type ConstDecl struct { Group *Group // nil means not part of a group Pragma Pragma NameList []*Name Type Expr // nil means no type Values Expr // nil means no values decl } // Name Type type TypeDecl struct { Group *Group // nil means not part of a group Pragma Pragma Name *Name Alias bool Type Expr decl }
以下が decl の宣言です。 decl は node という構造体を埋め込み、 node は Post という構造体を埋め込んでいますが、 Pos はただコード内の位置を持つだけの構造体です。
では、なぜ ConstDecl や TypeDecl は Pos を直接埋め込まずに decl を埋め込んでいるのでしょうか? 答えは aDecl() にあります。 aDecl() というこの何もしない関数は、実はどこからも呼び出されていませんが、 Decl インターフェイスは aDecl() を持つことを要求します。つまり、ここではダックタイピングを利用して、それぞれの構造体が「宣言」であるか否かを、 aDecl() という関数を持っているかどうかで判定しています。すぐにはパッと理解できないテクニックですが、面白いダックタイピングの使い方ですね。
type decl struct{ node } func (*decl) aDecl() {} type node struct { pos Pos } type Pos struct { base *PosBase line, col uint32 }
さて、話を戻します。 Package 句を構文解析する部分について見てみましょう。
p.got() と p.want() はそれぞれ以下のように現在のトークンを参照して情報を返します。
p.got()
トークンを読み進めた上で、現在見ているトークンが引数に与えた種類であるかを返す関数p.want()
トークンを読み進めた上で、現在見ているトークンが引数に与えた種類でなければエラーとする関数
p.got() と p.want() を使って構文をチェックし、問題がなければ f.PkgName にパッケージ名を格納します。
ちなみに、 p.takePragma() は // go:generate ... などのプラグマが書かれている場合はこれを取得する関数です。この場合は、ファイルの冒頭に書かれたプラグマを取得し、 File 構造体に持たせていますね。
cmd/compile/syntax/parser.go [開く]
func (p *parser) fileOrNil() *File {
if trace {
defer p.trace("file")()
}
f := new(File)
f.pos = p.pos()
// PackageClause
if !p.got(_Package) {
// 補足: 当然、パッケージ名が無ければ Syntax Error ですね
p.syntaxError("package statement must be first")
return nil
}
f.Pragma = p.takePragma()
f.PkgName = p.name()
p.want(_Semi)
次に、 import 文を構文解析する部分について見ていきます。
現在のトークンが import であれば、 p.appendGroup(f.DeclList, p.importDecl) で f.DeclList を append します。
// don't bother continuing if package clause has errors if p.first != nil { return nil } // 補足: 次にimport 文を構文解析する // { ImportDecl ";" } for p.got(_Import) { f.DeclList = p.appendGroup(f.DeclList, p.importDecl) p.want(_Semi) }
p.appendGroup(f.DeclList, p.importDecl) と p.importDecl() について見てみましょう。 まず p.importDecl() は、 ImportSpec を構文解析して ImportDecl を返します。
この p.importDecl() 関数をそのまま p.appendGroup(f.DeclList, p.importDecl) に渡しています。 appendGroup はコメントによれば f | "(" { f ";" } ")" を構文解析するようです。
つまり、 p.appendGroup(f.DeclList, p.importDecl) では "hoge" または ("hoge"; "fuga"; "piyo") のような文字列を構文解析し、得られた import 宣言をすべて f.DeclList に append しているようです。
cmd/compile/syntax/parser.go [開く]
// ImportSpec = [ "." | PackageName ] ImportPath . // ImportPath = string_lit . func (p *parser) importDecl(group *Group) Decl {
cmd/compile/syntax/parser.go [開く]
// appendGroup(f) = f | "(" { f ";" } ")" . // ";" is optional before ")" func (p *parser) appendGroup(list []Decl, f func(*Group) Decl) []Decl {
さて、package 句と import 文の構文解析が完了したら、次はトップレベルスコープにある定数、変数、型、関数を構文解析していきます。現在 scanner が見ているトークンが const であれば p.constDecl 、 var であれば p.varDecl など、それぞれ対応する関数に構文解析させ、結果を f.DeclList に追加します。つまり、この f.DeclList の中にトップレベルスコープで宣言された定数、変数、型、関数の情報がスライスの要素として格納されていきます。ファイル内のトップレベルスコープのすべての宣言について構文解析が完了した場合、そのファイルの構文解析は完了となります。
また、関数などの中でさらに変数や型や関数の宣言があれば、再帰的にこれを構文解析します。その辺りの処理が気になる場合は、 funcDeclOrNil 関数の実装を見ると良さそうです。
cmd/compile/syntax/parser.go [開く]
// { TopLevelDecl ";" }
for p.tok != _EOF {
switch p.tok {
case _Const:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
default:
if p.tok == _Lbrace && len(f.DeclList) > 0 && isEmptyFuncDecl(f.DeclList[len(f.DeclList)-1]) {
// opening { of function declaration on next line
p.syntaxError("unexpected semicolon or newline before {")
} else {
p.syntaxError("non-declaration statement outside function body")
}
p.advance(_Const, _Type, _Var, _Func)
continue
}
// Reset p.pragma BEFORE advancing to the next token (consuming ';')
// since comments before may set pragmas for the next function decl.
p.clearPragma()
if p.tok != _EOF && !p.got(_Semi) {
p.syntaxError("after top level declaration")
p.advance(_Const, _Type, _Var, _Func)
}
}
// p.tok == _EOF
p.clearPragma()
f.Lines = p.line
return f
}
AST への変換
gc.parseFiles
ここまでは、構文解析が cmd/compile/internal/syntax で行われ、 gc.parseFiles() にファイルごとの構文木が返されることを確認しました。
それでは、 gc.parseFiles() に戻り、今度は構文木から AST への変換処理について見ていきましょう。
gc パッケージは、syntax パッケージによって得られた File 構造体を受け取り、 Node 構造体で表現される AST へ変換します。
そして、その AST をたどって型チェックし、問題がなければ中間表現を生成します。
func parseFiles(filenames []string) uint { // 中略 // 補足: [STEP2] 構文木から AST へ var lines uint for _, p := range noders { for e := range p.err { p.yyerrorpos(e.Pos, "%s", e.Msg) } { /* highlight-range{1} */ } p.node() // 補足: AST への変換はここで行われる lines += p.file.Lines p.file = nil // release memory if nsyntaxerrors != 0 { errorexit() } // Always run testdclstack here, even when debug_dclstack is not set, as a sanity measure. testdclstack() } localpkg.Height = myheight return lines }
noder.node
それでは最後に、先程触れた p.node() でどのように AST への変換を行っているか少しだけ覗いてみましょう。 ちなみに noder というのはおそらく AST のノードを生成するための構造体だから node + er で noder という命名になっている、と私は推測しています。
まずは初期化処理をしています。
imported_unsafe はどこか一つのファイルで unsafe パッケージをインポートすると true になるグローバル変数です。
めちゃくちゃグローバル変数が多いですが、何かパフォーマンス上の問題があるのかもしれません。残念ながら、私は詳しい経緯や理由を追うことができませんでした。
mkpackage() はパッケージ名を取り出しています。
その後、プラグマが利用されているかどうかを記録しています。
func (p *noder) node() { types.Block = 1 imported_unsafe = false p.setlineno(p.file.PkgName) mkpackage(p.file.PkgName.Value) if pragma, ok := p.file.Pragma.(*Pragma); ok { p.checkUnused(pragma) }
ここが面白い
gc は、元々 C 言語で書かれていて、構文解析に yacc/bison を利用していました。 その後 gc は Go で書き直されましたが、 yacc/bison が利用されていた痕跡は今も残っています。
例えば、先程少しだけ触れた mkpackage() では yyerror() という関数を呼び出していますが、この yyparse という関数名は yacc/bison でのエラー処理のために定義する必要がある関数名と一致します。
もしコンパイラに興味があれば、 yacc/bison に触れてみるのもアリかもしれません。
func mkpackage(pkgname string) { if localpkg.Name == "" { if pkgname == "_" { yyerror("invalid package name _") } localpkg.Name = pkgname } else { if pkgname != localpkg.Name { yyerror("package %s; expected %s", pkgname, localpkg.Name) } } }
そして、次に File 構造体の DeclList プロパティからトップレベルスコープに定義された定数や関数などを持ってきて、これを p.decls で AST へ変換します。
xtop はトップレベルスコープにある宣言をすべて格納するグローバル変数です。
ここに格納された宣言は、後で1つずつ順番に型チェックされていきます[開く]。
func (p *noder) node() { types.Block = 1 imported_unsafe = false p.setlineno(p.file.PkgName) mkpackage(p.file.PkgName.Value) if pragma, ok := p.file.Pragma.(*Pragma); ok { p.checkUnused(pragma) } { /* highlight-range{1} */ } xtop = append(xtop, p.decls(p.file.DeclList)...)
p.decls の中身を見てみましょう。変数・定数・型・関数の宣言はそれぞれのハンドラで AST に変換された後に xtop へ格納されていきますが、import については特に型チェックが必要なわけではないので xtop には格納されていないことが分かります。
func (p *noder) decls(decls []syntax.Decl) (l []*Node) { var cs constState for _, decl := range decls { p.setlineno(decl) switch decl := decl.(type) { case *syntax.ImportDecl: p.importDecl(decl) case *syntax.VarDecl: l = append(l, p.varDecl(decl)...) case *syntax.ConstDecl: l = append(l, p.constDecl(decl, &cs)...) case *syntax.TypeDecl: l = append(l, p.typeDecl(decl)) case *syntax.FuncDecl: l = append(l, p.funcDecl(decl)) default: panic("unhandled Decl") } } return }
ここが面白い
上記のうち、 定数の AST への変換処理 constDecl() について見てみましょう。
以下のうち、ハイライト部分について着目して下さい。
なんと、 iota のカウンタの管理は、構文木から AST への変換の過程で行われていることが分かります。驚きですね。
- 直前まで見ていた定数宣言の状態
constStateと現在見ている定数宣言を比較し、同じconst ( ... )内で宣言された定数でなければconstStateをリセットする Node構造体を生成し、宣言された定数の名前と値を格納する- 宣言された定数に対応する
iotaの値をn.SetIota(cs.iota)で格納する cs.iota++でiotaのカウンタをインクリメントする
ちなみに、 iota の値を使うのか、宣言時に与えらた値を使うのかを決定する処理は型チェック時に行われるようです。
func (p *noder) constDecl(decl *syntax.ConstDecl, cs *constState) []*Node { { /* highlight-range{1-5} */ } if decl.Group == nil || decl.Group != cs.group { *cs = constState{ group: decl.Group, } } if pragma, ok := decl.Pragma.(*Pragma); ok { p.checkUnused(pragma) } names := p.declNames(decl.NameList) typ := p.typeExprOrNil(decl.Type) var values []*Node if decl.Values != nil { values = p.exprList(decl.Values) cs.typ, cs.values = typ, values } else { if typ != nil { yyerror("const declaration cannot have type without expression") } typ, values = cs.typ, cs.values } nn := make([]*Node, 0, len(names)) for i, n := range names { if i >= len(values) { yyerror("missing value in const declaration") break } v := values[i] if decl.Values == nil { v = treecopy(v, n.Pos) } n.Op = OLITERAL declare(n, dclcontext) n.Name.Param.Ntype = typ n.Name.Defn = v { /* highlight-range{1} */ } n.SetIota(cs.iota) nn = append(nn, p.nod(decl, ODCLCONST, n, nil)) } if len(values) > len(names) { yyerror("extra expression in const declaration") } { /* highlight-range{1} */ } cs.iota++ return nn }
まとめ
本記事では、コンパイラに関する知識をおさらいした上で、公式 Go コンパイラの一つである gc のコードを AST への変換部分まで見ていきました。 この中で、どれか一つでも「お、面白いじゃん」と思うような部分があれば嬉しいです。
ちなみに、Go の型システムに興味がある方は Featherweight Go を読んでみた という記事がおすすめです。
また、この記事をきっかけに gc やコンパイラに興味を持ってくれた方がいらっしゃれば Twitter などで教えて下さい。筆者がとても喜びます。
DeNA 公式 Twitter アカウント @DeNAxTech では、この Advent Calendar や DeNA の技術記事、イベントでの登壇資料などを発信しています。 もし良かったらフォローしてください。
付録 A: gc 以外の Go コンパイラ
gccgo
gccgo は GCC のフロントエンドで、もう一つの公式の Go コンパイルツールチェインです。 GCC は GNU Compiler Collection の略であり、様々なプログラミング言語に対応したコンパイルツールチェインです。 gccgo については golang.org/doc/install/gccgo にて解説されています。
gollvm
gollvm は LLVM のフロントエンドで、C++ で書かれた gccgo と共通のフロントエンド gofrontend を利用しています。 LLVM は特定の言語に依存しない中間言語 LLVM IR を用いることで、様々な言語に対応可能なコンパイラフレームワークです。 詳しくは go.googlesource.com/gollvm をご覧ください。

ライセンス
本記事に掲載された gc のコードについて
Copyright (c) 2009 The Go Authors. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name of Google Inc. nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.